Was ist Misa.C?
Der Minimal Sampling Classifier (MiSa.C) ist ein innovativer Webservice für die Klassifizierung von Fernerkundungs-Rasterbilddaten, der die Klassifizierung komplexer Oberflächen in Raum und Zeit ermöglicht. Der Dienst basierte auf dem Habitat Sampler (HaSa), einem Kommandozeilen-Tool, das von Dr. Carsten Neumann am Helmholtz-Zentrum Potsdam Deutsches GeoForschungsZentrum GFZ in Potsdam entwickelt wurde.
Die wichtigsten Vorteile von MiSa.C sind:
Es benötigt nur einen Referenzpunkt pro Klasse und eliminiert durch die automatische Generierung von Trainingspunkten die Notwendigkeit umfangreicher Ground-Truth-Daten.
Das Tool bietet eine Auswahl von zwei robusten Algorithmen für maschinelles Lernen zur Klassifizierung:
Random forest
Support vector machine
Nutzende haben vollständige Kontrolle über die Klassifizierung der Ergebnisse durch eine interaktive Einstellung der Klassifizierungsschwellenwerte in der benutzerfreundlichen grafischen Oberfläche. Diese berücksichtigt das Fachwissen von Sachkundigen, anstatt sich auf einen Black-Box-Algorithmus zu verlassen.
Die Eingabeparameter können während des gesamten Klassifizierungsprozesses angepasst werden, so dass die Nutzenden Resultate beobachten und nur dann fortfahren können, wenn sie mit den Ergebnissen zufrieden sind.
MiSa.C bietet eine einfache Ausgabe von Ergebniskarten und Bildern.
Das Tool unterstützt die Eingabe von Rasterbildern von verschiedenen Sensoren und Auflösungen.
Optional: Nutzende haben die Möglichkeit, vorverarbeitete, atmosphärisch korrigierte Sentinel-2-Zeitreihendaten direkt über das Interface herunterzuladen und als Eingabedaten zu nutzen.
Wie funktioniert es?
Die MiSa.C-Benutzeroberfläche führt die Nutzenden Schritt für Schritt durch den Klassifizierungsprozess mit den folgenden Hauptschritten:
Schritt 0: Erstellen eines Arbeitsbereichs, indem ihm ein eindeutiger Name und optional eine Beschreibung gegeben wird.
Schritt 1: Hinzufügen repräsentativer Referenzdaten, indem ein Shapefile oder Tabellendaten hochgeladen werden.
Schritt 2: Hochladen eines Layer-Bildstapels, indem entweder ein eigener Datenstapel verwendet, oder auf Sentinel-2 Daten vom internen Download-Service zugegriffen wird.
Schritt 3: Ausführen des interaktiven, schrittweisen Klassifizierungsalgorithmus, der die Ergebnisse für jeweils eine Klasse ausgibt. Die Nutzenden können den Klassifizierungsprozess für eine einzelne Klasse so lange wiederholen, bis sie mit den Ergebnissen zufrieden sind, bevor sie zur nächsten Klasse übergehen.
Ergebnisse Die Ergebnisse können in der Kartenansicht von MiSa.C angezeigt oder zur weiteren Analyse mit externen Tools heruntergeladen werden.
Den MiSa.C-Klassifizierungsprozess kennenlernen
Dieses Tutorial führt durch den Klassifizierungsprozess in MiSa.C und bietet Erklärungen für jeden Schritt. Außerdem werden Lösungen angeboten, die dabei helfen, ein zufriedenstellendes Klassifizierungsergebnis zu erzielen.
Schritt 0: Erstellung eines Arbeitsbereiches
Bevor mit der Klassifizierung begonnen wird, muss ein neuer Arbeitsbereich (“workspace”) erstellt werden. In diesem Arbeitsbereich kann dem Projekt oder Standort ein aussagekräftiger Name und optional eine Beschreibung gegeben werden. Nutzende kann bis zu 15 Arbeitsbereiche anlegen.
Hinweis: Wenn bereits ein Arbeitsbereich mit demselben Namen existiert, kann die Bezeichnung nicht erneut verwendet werden.
Schritt 1: Eingabe der Referenzdaten
Sobald ein Arbeitsbereich erstellt wurde, können Nutzende repräsentative Referenzdaten hochladen. MiSa.C
bietet dafür zwei Möglichkeiten: das Hochladen eines ESRI-Shapefiles im .zip-Format oder das Hochladen
von Daten aus einer Tabelle im .txt-Format. Beim Hochladen eines ESRI-Shapefiles werden die Standorte
der Referenzdaten bzw. der Referenzpunkte (einer pro Klasse) hochgeladen und die Klasseninformationen werden
direkt aus den Daten an den angegebenen Punktstandorten abgerufen. Es ist wichtig zu beachten, dass sich
alle Referenzpunkte innerhalb des zu analysierenden Gebiets befinden müssen. Wenn die Referenzpunkte
verstreut sind und nicht direkt im zu analysierenden Gebiet liegen, können die
Spektralinformationen auch über eine Referenzdatentabelle hochgeladen werden. Schließlich muss die Anzahl der
Referenzdatenwerte pro Klasse genau der Anzahl der Schichten (Daten x Spektralbänder) des Rasterstapels
entsprechen.
Option A) Shapefile
Die Nutzenden stellen die repräsentativen Referenzdaten als Shapefile zur Verfügung, wobei sich alle Punkte innerhalb des analysierten Bereichs befinden.
Repräsentative Referenzdaten, die in einem Shapefile gespeichert sind, müssen Punktdaten enthalten, und zwar einen Punkt pro Klasse. Für jeden Punkt im Shapefile der Referenzdaten muss außerdem der entsprechende Klassenname in einer eigenen Spalte mit dem Namen “class” gespeichert sein. Klassennamen dürfen keine Sonderzeichen, Umlaute oder Leerzeichen beinhalten. Optional können nach dem Hochladen der Referenzdaten die Klassen, die nicht für die Klassifizierung verwendet werden sollen, abgewählt werden.
Die erforderlichen Formate für ein Shapefile aus einem lokalen Verzeichnis sind:
*.dbf
*.prj
*.shp
*.shx
Hinweis: Derzeit unterstützt MiSa.C maximal 20 Klassen für einen Klassifizierungslauf. Das Shapefile muss außerdem über eine geografische Projektionsinformation verfügen. MiSa.C passt die Projektion automatisch an, wenn sie nicht mit der Projektion der eingegebenen Rasterdaten übereinstimmt.
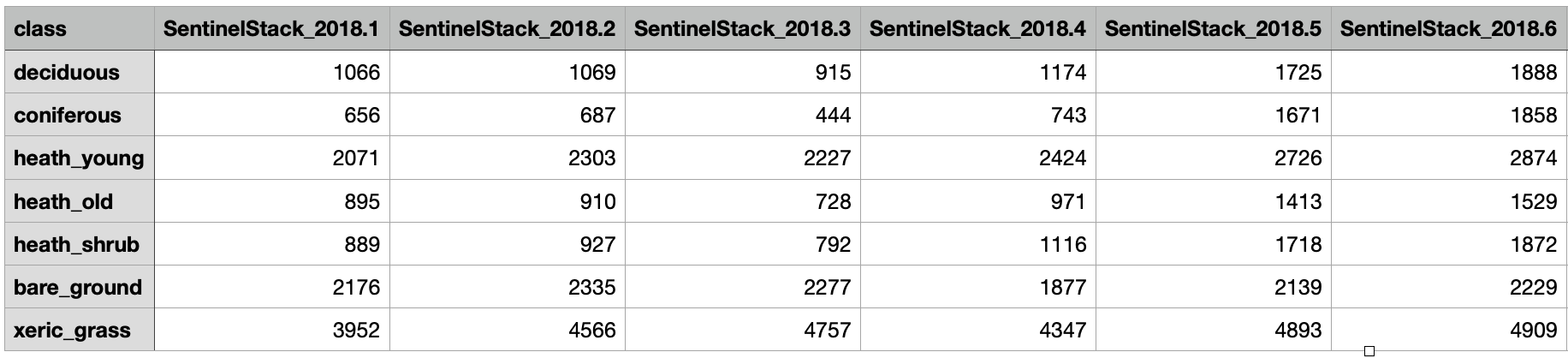
Option B) Tabellarische Datei
Wenn die Nutzenden über repräsentative Referenzdaten verfügen, die sich nicht im Interessengebiet befinden, aber die gleichen Bandinformationen enthalten.
Repräsentative Referenzdaten, die sich nicht in dem betreffenden Gebiet befinden, können als Tabelle im
.txt-Format hochgeladen werden. Die erste Spalte sollte die Klassennamen enthalten und die erste Zeile die
entsprechenden Bändernamen. Die Tabelle mit den Referenzdaten sollte so formatiert sein, wie in der Abbildung
unten dargestellt.
MiSa.C validiert die Eingabe des Bildebenenstapels, um zu prüfen, ob die Anzahl der Referenzdatenwerte pro Klasse mit der genauen Anzahl der Schichten (Daten x Spektralbänder) des Rasterstapels übereinstimmt. Wenn die Überprüfung fehlschlägt, können die Nutzenden nicht fortfahren. Diese Option kann nicht in Kombination mit dem Download-Service verwendet werden, da in diesem Fall die Bandinformationen nicht abgeglichen werden können.
Schritt 2: Eingabe eines Bildebenenstapels
Es gibt zwei Möglichkeiten, einen Bildebenenstapel hinzuzufügen. Die eine ist der eingebaute Download-Service, der nur verfügbar ist, wenn die repräsentativen Referenzdaten im Shapefile-Format vorliegen. Die andere Möglichkeit ist das Hochladen eines lokalen Bildebenenstapels.
Hinweis: Nach dem Hochladen eines Bildebenenstapels ist es möglich, die Tabelle mit den repräsentativen Referenzdaten in MiSa.C anzuzeigen.
Option A) Lokalen Bildebenenstapel hochladen
Bevor der eigentliche Bildebenenstapel hochgeladen wird, ist eine zusätzliche Beschreibungsdatei im
.json-Format erforderlich. Im Abschnitt JSON-Beschreibungsdatei laden - Anforderungen wird beschrieben,
wie sie formatiert sein sollte.
Danach kann ein lokaler Bildebenenstapel hochgeladen werden. Die Anforderungen dafür sind ebenfalls im Abschnitt Lokalen Bildebenenstapel laden - Anforderungen an Rasterdaten beschrieben.

Option B) Bildebenenstapel über den Download-Service
MiSa.C verfügt über einen integrierten Download-Service, der atmosphärenkorrigierte Sentinel-2-Bilder zur Verfügung stellt, indem die Nutzenden
den gewünschten Zeitraum,
die gewünschten Bänder,
das gewünschte Interessengebiet entweder durch Zeichnen eines Begrenzungsrahmens wählen oder durch Verwendung eines Shapefiles im
.zip-Format.
Die ausgewählte Fläche kann bis zu 120km² umfassen. In einem ersten Schritt werden die für den gewählten Zeitraum verfügbaren Daten angezeigt. In dieser Liste können zwischen 3 und 12 Daten für die Klassifikation ausgewählt werden. Nachdem das Häkchen zur Zustimmung zu den Geschäftsbedingungen (“terms and conditions”) gesetzt wurde, können die Daten heruntergeladen werden. Sobald der Bildebenenstapel in MiSa.C geladen ist und ein Shapefile für die repräsentativen Referenzdaten verwendet wurde, sollte der Nutzer sowohl die zuvor hochgeladenen Referenzpunkte als auch die Satellitenbilder sehen. Dies sollte ähnlich wie in der folgenden Abbildung aussehen:

Überprüfung auf Wolkenbedeckung im Bildebenenstapel
Falls der eingebaute Download-Service verwendet wird, müssen die Nutzenden ihre Bildebenenstapel auf mögliche Wolkenbedeckung überprüfen, da es sonst zu Fehlern in der Oberflächenklassifizierung kommt.
Dazu müssen die Nutzenden auf den Button Add a new RGB layer klicken. Im neu geöffneten Tab muss für jede
RGB-Komponente des Stapels das gleiche Datum ausgewählt werden. Nachdem dem Layer ein aussagekräftiger Name gegeben und
auf Create geklickt wurde, wird der Layer automatisch an oberster Stelle auf der Karte angezeigt, sodass
dieser direkt auf Wolkenbedeckung überprüft werden kann. Wird Wolkenbedeckung festgestellt, muss der Layer von der
Klassifikation ausgeschlossen werden (Klassifizierungsprozess). Diese Überprüfung muss für jedes Datum wiederholt
werden.

JSON-Beschreibungsdatei laden - Anforderungen
Um den Upload des lokalen Bildebenenstapels zu starten, müssen die Nutzenden eine Beschreibungsdatei hochladen,
die die Daten jeder Szene im Rasterstapel und die Bandnamen enthält. Mit diesen Informationen über die Daten
und die Bänder können benutzerdefinierte RGB-Ebenen erstellt werden, die während der Klassifizierung als
Referenz verwendet werden können. Die Beschreibungsdatei wird als .json-Datei in folgendem Format hochgeladen:
{
"dates": ["YYYY-MM-DD", "YYYY-MM-DD", ...]
"bands": ["band name 1", "band name 2", ...]
}
Es dürfen maximal 12 Daten vorhanden sein. Optional können Nutzende auch Informationen über die in den Daten verwendeten NoData-Werte angeben. Pixel mit diesen Werten werden dann von der Klassifizierung ausgeschlossen:
{
"dates": ["YYYY-MM-DD", "YYYY-MM-DD", ...]
"bands": ["band name 1", "band name 2", ...]
"nodata": ["0", ...]
}
Eine .json-Vorlage für jeden benutzerdefinierten Datenstapel ist
hier
verfügbar.
Lokalen Bildebenenstapel laden - Anforderungen
Um mit MiSa.C zu arbeiten, müssen alle Rasterdaten zu einem einzigen Datenstapel zusammengefasst werden, wie im folgenden Beispiel gezeigt:
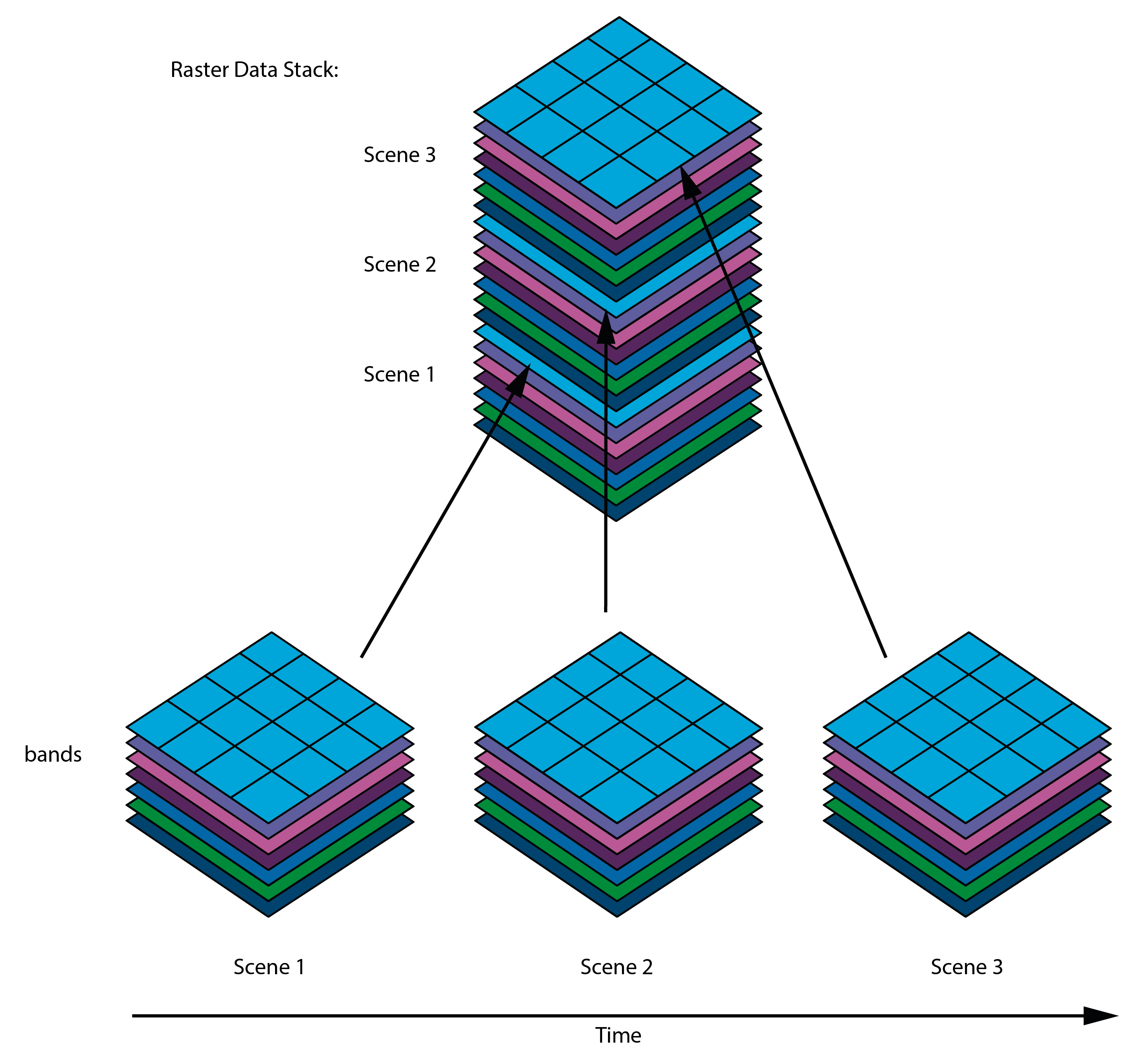
Alle Ebenen im Rasterdatenstapel müssen die gleiche räumliche Ausdehnung haben.
Alle Pixel im Rasterdatenstapel müssen die gleiche räumliche Auflösung und die gleiche Projektion haben.
Das Koordinatenreferenzsystem (CRS) muss in UTM definiert sein.
Alle Pixel müssen aussagekräftige Informationen enthalten. Der Algorithmus kann nicht richtig funktionieren, wenn einige Pixel von Wolken bedeckt sind. Es liegt in der Verantwortung des Nutzers, die Daten entsprechend aufzubereiten.
Alle einzelnen Bildszenen müssen genau die gleichen Bänder enthalten (Anzahl der Bänder und spektrale Informationen).
Die Ebenen sollten zeitlich korrekt geordnet sein, d.h. das älteste Bild (erstes in der Zeit) kommt nach unten und das neueste (letztes in der Zeit) nach oben.
Die maximale Größe eines Rasterdatenstapels darf 250 MB nicht überschreiten.
Die Bit-Tiefe des Rasterdatenstapels muss 32 Bit entsprechen.
Schritt 3: Oberflächenklassifizierung
MiSa.C verstehen
Um besser zu verstehen, was MiSa.C tut, finden sich im Folgenden einige Hintergrundinformationen:
Sampling: MiSa.C nimmt Stichproben und erkennt automatisch Pixel mit ähnlichen spektralen Eigenschaften. Die automatische Suche nach Trainingsdaten kann entweder mit einem regelmäßigen Raster von Pixeln oder durch Testen zufälliger Pixel auf Ähnlichkeit erfolgen. Es ist zu beachten, dass ein regelmäßiges Raster von Stichproben schneller ist als ein zufälliges. Es scheitert jedoch, wenn viele NoData-Werte vorhanden sind, da eine zunehmende Anzahl von Punkten in diese Bereiche fällt. Dies geschieht auch, wenn mehr und mehr Pixel bereits einer Klasse zugeordnet sind. Die Zufallsauswahl ist langsamer, nimmt aber nur Pixel innerhalb gültiger, nicht klassifizierter Pixel auf. Wenn die Klassifizierungsergebnisse nicht zufriedenstellend sind, sollten Nutzende versuchen, die Anzahl der Stichproben zu erhöhen und die Stichprobenverteilung zu ändern.
Modellierung: Basierend auf der automatischen Auswahl der Trainingspunkte, versucht der gewählte Algorithmus für maschinelles Lernen, so viele Modelle zu erstellen, wie mit dem Parameter “number of models” spezifiziert wurde. Anschließend werden diese Modelle darauf getestet, ob sie eine Klasse von allen anderen anhand der angegebenen Referenzdaten unterscheiden können. Wenn dies der Fall ist, wird dieses spezielle Modell gespeichert. Nachdem alle Modelle und alle Klassen getestet wurden, wird die Klasse mit den meisten Modellen ausgewählt. MiSa.C verwendet dann eines dieser spezifischen Modelle für die ausgewählte Klasse, um zu entscheiden, ob ein Pixel des Bilddatenstapels zu der angegebenen Klasse gehört oder nicht. Dies geschieht mehrmals, je nach Anzahl der für diese Klasse gewählten Modelle. Anschließend zeigt die Karte die Ergebnisse an. Die Ergebnisse sind in diesem Zusammenhang die Anzahl der Modelle, die eine Klasse eindeutig von den anderen Klassen trennen können. Wenn das Klassifizierungsergebnis nicht zufriedenstellend ist, können Nutzende den für die Klassifizierung verwendeten Algorithmus ändern oder die Anzahl der Modelle erhöhen.
Anpassung: Für jeden Schritt zeigt MiSa.C die Anzahl der Modelle an, die ein bestimmtes Pixel als zu einer Klasse gehörig identifiziert haben. Je höher die Anzahl der Modelle, desto höher ist die Wahrscheinlichkeit, dass das Pixel richtig klassifiziert wird. MiSa.C ermöglicht es den Nutzenden, ihr Fachwissen einzubeziehen, um einen guten Schwellenwert für die Anzahl der Modelle, die die Pixel richtig klassifiziert haben, zu bestimmen. Dabei ist zu beachten, dass mit weniger verbleibenden Klassen die Anzahl der Modelle, die Pixel einer bestimmten Klasse zuordnen, steigt. Wenn das Klassifizierungsergebnis nicht zufriedenstellend ist, sollte von der Möglichkeit Gebrauch gemacht werden, eine erneute Stichprobe durchzuführen – entweder mit denselben Eingabeparametern oder, wenn die wiederholte Stichprobe das Ergebnis nicht verbessert, mit angepassten Parametereinstellungen.
Klassifizierungsprozess
Mit dem Button Start classification können Nutzende den Prozess der Oberflächenklassifizierung beginnen. Es öffnet
sich eine Registerkarte, die die Anzahl der verfügbaren Klassifizierungsschritte, den aktuellen Schritt und die
verschiedenen Parameter anzeigt, die für die Klassifizierung angepasst werden können. Die Registerkarte zeigt auch an,
welche Daten ausgewählt wurden und welche Bänder verwendet werden. So kann überprüft werden, ob die richtigen
Entscheidungen getroffen wurden.
Die einstellbaren Parameter sind
Initial Number of Samples (Anfangsanzahl Stichproben)
Initial Number of Models (Anfangsanzahl Modelle)
und in den erweiterten Einstellungen
Band selection (Band-Auswahl): Die Nutzenden können bestimmte Bänder oder ganze Szenen (ab-)wählen. In den Standardeinstellungen sind alle Bänder und Szenen ausgewählt. Wenn der interne Downloadservice verwendet wurde, ist es an dieser Stelle wichtig das gesamte Datum abzuwählen, falls bei der Überprüfung (Überprüfung auf Wolkenbedeckung im Bildebenenstapel) Wolken festgestellt wurden.
Machine Learning Algorithm (Algorithmus für maschinelles Lernen): Die Optionen sind Random Forest und Support Vector Machine. Standardmäßig ist Random Forest ausgewählt.
Sample Type (Stichprobentyp): Die Optionen sind regular raster (reguläres Raster), random raster (Zufallsraster) und random matrix (Zufallsmatrix). Die Standardeinstellung ist regular_raster. regular_raster ist schnell, verwendet aber ein regelmäßiges Raster, das alle Pixel zu jeder Zeit einschließt, einschließlich der NaN-Werte, was es zu Beginn der Klassifizierung zu einer guten Wahl macht. Mit fortschreitender Klassifizierung werden immer mehr Pixel herausgeschnitten, weil sie einer Klasse zugeordnet wurden. Diese Pixel erhalten dann NaN-Werte. In diesem Fall ist die Zufallsmatrix die bessere Wahl. Sie ist langsamer, berücksichtigt aber nur die Pixel mit Werten.
Threshold (Schwellenwert für den Modellfehler) (0.00-1.00): Während der Modelltrainingsphase werden die Modelle so lange trainiert, bis ihr Fehler weniger als 0.02 beträgt (das bedeutet, dass die Modelle eine Genauigkeit von 98% erreichen). Wenn die Ergebnisse nicht zufriedenstellend sind, können die Nutzende versuchen, diesen Wert etwas zu lockern (z. B. bis zu 0.05).
Predictors (Anzahl der Prädiktoren): Um die Zufälligkeit in einem Random-Forest-Verfahren zu gewährleisten, muss die Anzahl der Prädiktoren immer kleiner sein als die Anzahl der Eingabebänder. Außerdem muss es eine ungerade Anzahl sein. Der empfohlene Wert wird auf der Grundlage der Eingabedaten berechnet. Der Standardwert sollte \(N_{\text{pred.}}=\sqrt{N_{\text{layers}}}\) sein (falls diese Zahl nicht ungerade ist: +1).
Distance (meter) (Abstand (in m)) (hängt von der Pixelgröße ab): Standardmäßig wird ein Puffer der 8 benachbarten Pixel einer Probe auf ihre Ähnlichkeit mit dem Probenpixel überprüft. Der Abstandswert bezieht sich auf die Länge des Radius vom Mittelpunkt des Probenpixels zum Mittelpunkt des diagonal angrenzenden Pixels (in m). Exakt: \(\text{buffersize} = \sqrt{\text{pixRes}^{2} + \text{pixRes}^{2}} \cdot 1.05\), wobei pixRes die räumliche Auflösung der Daten angibt. Die Puffergröße sollte immer gleich oder größer sein als der Radius vom Zentrum eines Pixels zum Zentrum des diagonalen Nachbarn. Nutzende haben die Möglichkeit, die Puffergröße zu erhöhen (der Wert sollte schrittweise erhöht werden, wie \(2.05 \cdot x\), \(3.05 \cdot x\) , \(4.05 \cdot x\) , …).
Es gibt nicht die eine Einstellung, die für alle passt – die Wahl der geeigneten Standardparameter hängt von den Daten und dem Ziel der Klassifizierung ab. Es ist auch wichtig zu wissen, dass die Wahl des Algorithmus für maschinelles Lernen die Klassifizierungsergebnisse ebenfalls beeinflussen kann. Verschiedene Algorithmen haben unterschiedliche Stärken und Schwächen, und einige können bei bestimmten Datentypen oder für bestimmte Klassifizierungsaufgaben besser abschneiden.
Es empfiehlt sich, mit den Standardwerten zu experimentieren, um ein besseres Gefühl für die Kompromisse zwischen
der Anzahl der erhaltenen Modelle (und damit der Feinabstimmung des Ergebnisses) und der MiSa.C-Verarbeitungszeit zu
bekommen. Ein guter Arbeitsablauf für MiSa.C ist es, mit kleinen Zahlen zu beginnen, um einen schnellen Eindruck vom
Ergebnis zu bekommen und die Bearbeitungszeit kurz zu halten. Wenn das Ergebnis nicht zufriedenstellend ist, sollten
die Werte Schritt für Schritt erhöht werden. Es ist also am besten, zunächst die Standardparameter zu verwenden. Wenn
die Nutzenden mit dem Ergebnis nicht zufrieden sind und die Parameter ändern möchten, können sie auf die Schaltfläche
Reclassify klicken und die Werte für die Klasse ändern.
Schieberegler für den Schwellenwert
Sobald das Ergebnis für die gewünschte Klasse vorliegt, muss der Schwellenwert für die Pixel, die in der entsprechenden
Klasse verbleiben sollen, interaktiv mit dem Schieberegler eingestellt werden. Der Schwellenwert gibt die Anzahl der
Modelle an, die das Pixel einer bestimmten Klasse zugeordnet haben. Nutzende können dies nun für alle verfügbaren
Klassen tun. Wenn nicht alle Klassen klassifiziert werden sollen, kann der Prozess mit dem Button End classification,
save and show results gespeichert und beendet werden.
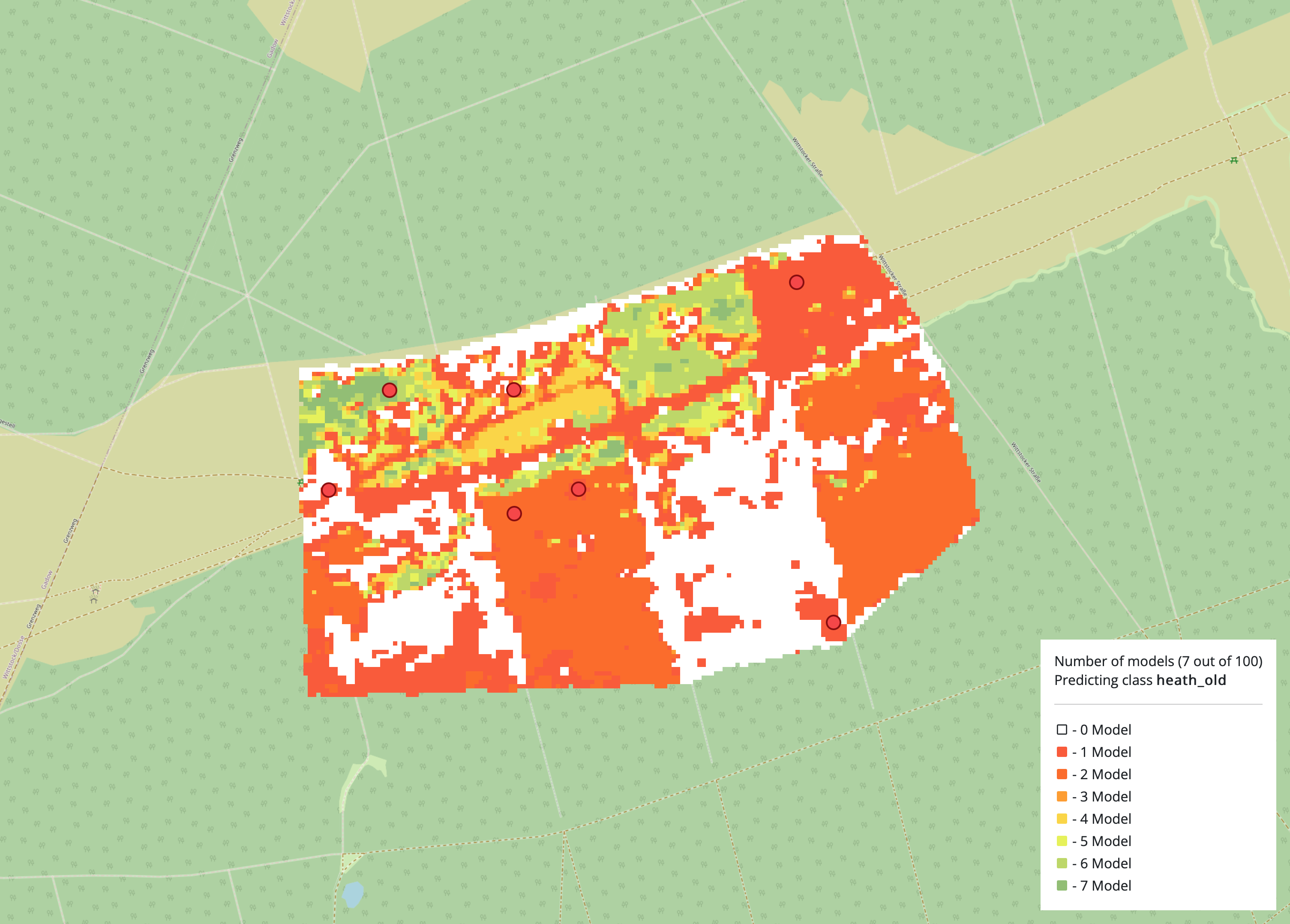
Ergebnisse
Das Ergebnis des Klassifizierungsprozesses wird automatisch im Arbeitsbereich der Nutzenden gespeichert, und die Ergebniskarte wird mit allen Klassen angezeigt, einschließlich der nicht klassifizierten Pixel als Klasse “other”. Die Ergebnisse, der ursprüngliche Bilddatenstapel und die Metadaten stehen nach dem Aktualisieren der Seite in der Arbeitsbereichs-Verwaltung zum Download bereit.
Hinweis: Die Ergebnisse, der ursprüngliche Bilddatenstapel und die Metadaten können durch erneutes Laden der MiSa.C-Webanwendung heruntergeladen werden. Die Schaltfläche zum Herunterladen ist innerhalb des “workspace management” zu finden.
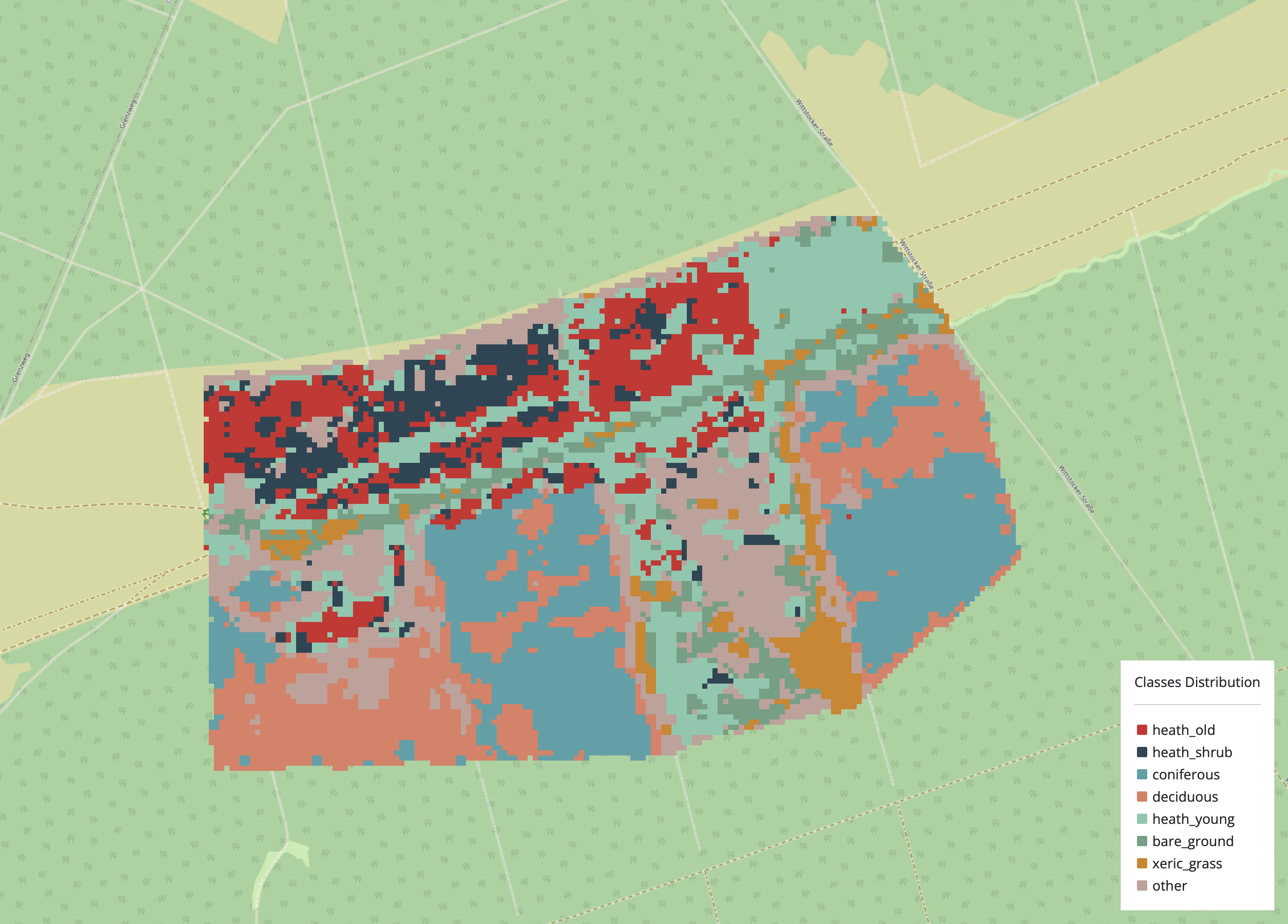
Zu den herunterladbaren Ergebnissen gehört auch die Ergebniskarte. Sie zeigt alle klassifizierten und nicht klassifizierten Pixel in einer einzigen .tif-Datei an und bietet einen klaren Überblick über alle Klassen. Auf diese Weise lassen sich die Ergebnisse leicht anzeigen, für die weitere Verarbeitung verwenden oder Fehler oder Bereiche, die weitere Aufmerksamkeit erfordern, identifizieren.
Einbettung von Vektor- und Rasterebenen in QGIS
Rasterdaten können über eine WMS/WMTS-Verbindung in QGIS eingebettet werden. Dazu müssen die Nutzenden auf das Icon zum Kopieren des Links in die Zwischenablage der gewünschten Klasse in der Ebenenverwaltung auf der rechten Seite klicken.
Der kopierte Link kann in QGIS unter Layer > Layer hinzufügen > WMS/WMTS-Layer hinzufügen... verwendet werden. Hier
müssen die Nutzenden anschließend auf ``Neu klicken, wo der kopierte Link in das Feld URL mit einer schlüssigen
Bezeichnung unter Name eingetragen werden kann. Nach einem Klick auf OK erscheint die Option zum Verbinden,
woraufhin der der zur Verfügung stehende Layer ausgewählt werden und in das QGIS-Projekt hinzugefügt werden kann.
Vektordaten können auch über einen neuen Layer in QGIS eingebettet werden. In der oberen linken Ecke
auf das Symbol für den Datenquellenmanager > Vektor > Quellentyp > Protokoll: HTTP(S), Cloud, etc. klicken, dann
unter Protokoll > Typ HTTP, HTTPS, FTP wählen und den kopierten Link ins Feld URI einfügen.
Fehlerbehebung
Die Oberflächenklassifizierung kann unter bestimmten Umständen zu Klassifizierungsfehlern führen. Dies geschieht, wenn die Anzahl der verbleibenden Proben oder Modelle nicht ausreicht, um gültige Modelle zu erhalten. Eine andere Möglichkeit für Fehler besteht darin, dass der für jede Klasse gewählte Schwellenwert zu niedrig ist, so dass nur eine geringe Anzahl von Pixeln für eine der späteren Klassen übrig bleibt. Es wird eine Registerkarte eingeblendet, die den Nutzenden mitteilt, welche Parameter geändert werden müssen, um Ergebnisse zu erhalten. Wenn das Problem weiterhin besteht, ist es auch möglich, zu einem anderen Algorithmus für maschinelles Lernen oder einem anderen Probentyp zu wechseln oder die erweiterten Parameter zu erhöhen.
Tutorials
Tutorial 1: Klassifizierung eines benutzerdefinierten Bildstapels mit vorhandenen Referenzdaten.
Tutorial 2: Verwendung des Downloaders.